In League, a single action can determine the outcome of a lane, or even the game. For this reason, randomness in the game is a tricky topic. While landing a huge critical strike (crit) on your opponent can be satisfying, being the victim of a “lucky” crit can be frustrating, or worse: a random event could cause a skilled player to lose to a less-skilled player, even though the skilled player made a better play. In a casual game, the decision to include randomness might be a no-brainer, if it makes the game more fun. However, the decision to include randomness in Esports has the potential to make or break a pro player’s career or determine the outcome of a tournament. As a result, many game developers take measures to reduce the influence of randomness in their games. Riot themselves made such a decision in Season 1, when they decided to change how critical strikes operate.
It used to be the case that attacks were independent, meaning that each attack had the same chance to crit, regardless of prior attacks. For example, at 50% crit chance, the probability of getting two crits in a row (a “crit chain” of length two) was the same as any other combination of two outcomes. In other words, whether you just crit or not, your probability of critting on the next attack was still 50%. However, to make the probability of extreme outcomes (like double crits) less likely, Riot decided to employ an algorithm for what we call “crit smoothing,” intended to decrease the probability to crit when the previous attack was a crit, and vice versa. To quote Riot’s patch v1.0.0.109 release notes in January 2011, “We have changed how critical strike and dodge chance work. You will now get fewer ‘lucky’ or ‘unlucky’ streaks where you get no critical hits/dodges in a row, or a lot of them in a row. Your average chance to get a crit is the same as before though—if you have a 50% crit rate, and you make 100 attacks, you’ll still crit about 50 times.”
Results: Crit Rates
To our knowledge, Riot has never shared its crit smoothing algorithm—so, we decided to see if we could use data to figure it out. We spent over nine hours recording videos of sequences of attacks in the practice tool, and wrote Python scripts to read this video into sequences of 1’s and 0’s, for crits and non-crits.
What we found was truly... striking.
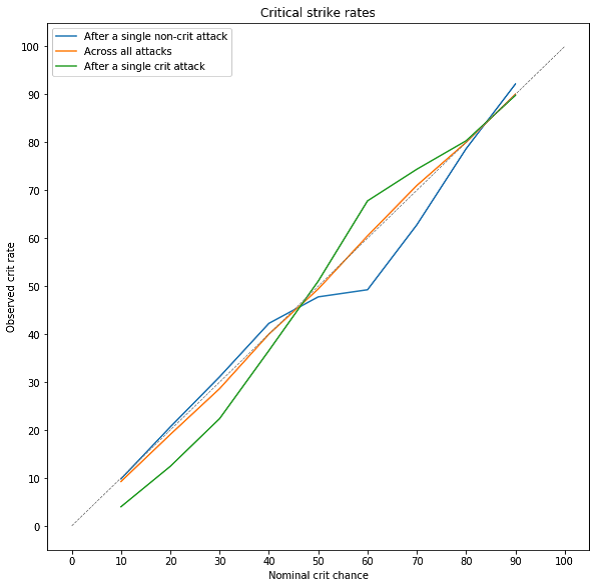
On the x-axis is the crit chance Riot says you have. On the y-axis is the crit chance we actually observe. The three colored curves show the rates for (1) all attacks together, (2) attacks that happened after a crit, and (3) attacks that happened after a non-crit. In grey, we show the line y=x, which is what you’d expect to see for all three curves if there was no crit smoothing at all.
The graph above shows the observed crit rate (the percentage of attacks we observed in the video that crit) for different values of in-game displayed crit chance, which we call “nominal crit chance.” (We chose this term to make it extra clear that in-game displayed crit chance is not the same as your actual crit chance is for a specific attack.) The three colored curves show the observed rate for three kinds of attacks: attacks that happened after a crit, attacks that happened after a non-crit, and all attacks.
What you see in this plot is pretty amazing—it says that for (nominal) crit chances under 50%, Riot applies crit smoothing like we expected: you are less likely to crit again after you crit once. However, above 50%, Riot does the opposite of smoothing. At high crit chances, crits become more likely after crits, and non-crits become more likely after non-crits. This means streaks are even more common than if Riot did not modify crit chances.
Looking at the plot above, you can see that at 10% crit chance from items (nominal crit chance), an attack after a crit has only a 4% chance to crit again, as shown by the green line. This is less than half the nominal crit chance! The overall crit chance (orange line) fluctuates slightly from x=y (the grey dashed line) which is what the overall crit rates would be if attacks were independent. Initially, we believed that after a crit the chance of a crit on the next attack would drop and after a non-crit it would increase, according to Riot’s patch notes. At low crit rates, crit smoothing occurs as expected. However, we see the reverse starting at around 50% until 80%. This indicates that after you get a crit, on average you are more likely to crit again. For a closer look at these values, the table below contains the overall crit chance and crit or non-crit chains of up to two attacks for various nominal crit values available as of patch 8.14.
This table shows crit rates under different conditions. When set to “Observed,” each column contains the observed crit rate after a certain number of attacks, and cells are colored according to how different the observed rate is from the theoretical rate (with independent attacks). Red means that crits are more likely than you would expect under independent attacks, and blue means that crits are less likely than you would expect under independent attacks.
Data Processing
All of the above analyses were based on data gathered by reading the pixel values in over nine hours of practice game footage. In order to calculate the percentages, we gathered a large number of attacks across different crit chances by recording videos in the practice tool. After the video was recorded we wrote a Python program to detect crits and non-crits for us. We needed to write code that would take a video and use the RGB values to return a list of 1s and 0s corresponding to crits and non-crits. This alone was a challenge, but the task didn’t end there: we had to come up with a way to ensure that the 1s and 0s returned by the code were correct. Otherwise, we couldn’t be sure that the data it returned was meaningful.

This is the region of the screen our program used to detect crits or non-crits.
The problem of detecting crits by analyzing video seemed daunting, so we tried to simplify our data as much as possible before diving into crit detection. First, we treated the video as a sequence of still images (frames), so we only had to process one frame at a time. We also picked a small region of the screen that contained most of the action for crits (shown above), so we could ignore the rest of the screen. Then, we made one more big simplification: instead of treating each pixel separately and using its specific RGB (red, green, blue) values, we took the average of all pixels in the region to get an overall average RGB value for the entire frame. This way, instead of having to analyze an entire image, we just had to analyze three numbers: average red, average green, and average blue. These numbers for a short segment of video are shown in the plot below.
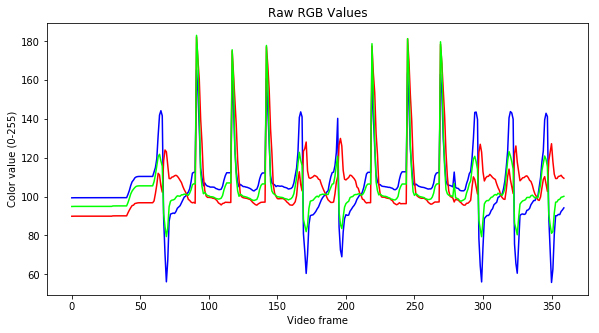
These are the average RGB values of our video across a few hundred frames.
This plot is encouraging, because there are clear spikes in RGB values that correspond to crit attacks and non-crit attacks. This means that our choice to ignore most of the video data and only look at average RGB for each frame is probably going to work out!
Next, in order to be able to process this data more reliably (and for it to be more visually intuitive) we modified the RGB values by multiplying and shifting them by different amounts. The purpose of this was to change the values so that it would become easy to define a few simple rules for determining when an attack was a crit or not. An example of a simple rule would be “if blue goes over 300, then we say that a crit attack just started.”
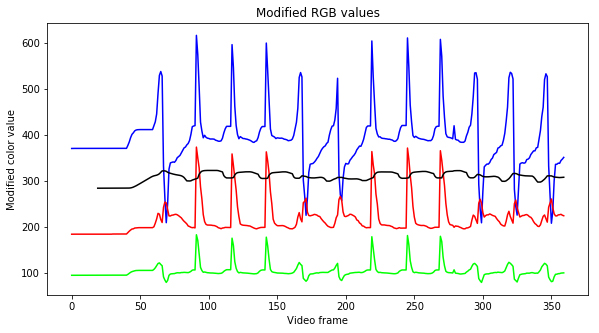
These are RGB values used to determine crits. The x-axis represents the frames at which they occurred and the y-axis represents the modified RGB values. Each line represents a modified RGB or the average (in black).
By comparing the videos to these graphs, we determined that they can be read as follows: a large spike in blue and red is a non-crit (0), while a decrease in blue with a subsequent minor spike in red is a crit (1). While a human can easily pick out patterns and tell what happened, it’s a tricky challenge to write instructions to a computers to do the same thing. To verify that our program was accurate and to avoid manual inspection of the crit values it detected, we went through a lot of tests and thought about ways to reduce the amount of manual checking of videos that we’d have to do. Our final iteration of code read the RGB values of a portion of the screen and determined whether each frame of video was a crit, non-crit, or in between attacks.
It turns out, even this seemingly simple task came with many challenges.
There were two types of errors we focused on detecting: (i) not recognizing that an attack occured at all (“skipping”) and (ii) reading two attacks in a short time span, when in fact only one attack happened (“double counting”). We could not say that each attack happened after a set number of frames because it was not possible to keep the same attack speed across multiple crit chances, due to the differences in items required to obtain different crit chances. This was difficult to solve and required us to check the number of frames between attacks. (Our videos were recorded at 30 frames per second.) If the number of frames between attacks were too high or too low we flagged it as a potential error. As these were possible sources of error, we had our code print the values for us, and saved them to an error folder where we could manually inspect them and determine whether they were correct or not. With around 25 potential errors per video, someone could manually inspect the graphs for whether it was truly an error or not. The most common potential errors that we flagged were instances where the person recording the video had to move so they would not be kicked by the League client for being AFK. As we improved our algorithm for detecting crits, the number of potential errors became smaller and smaller. For our final algorithm, we found no true errors flagged.
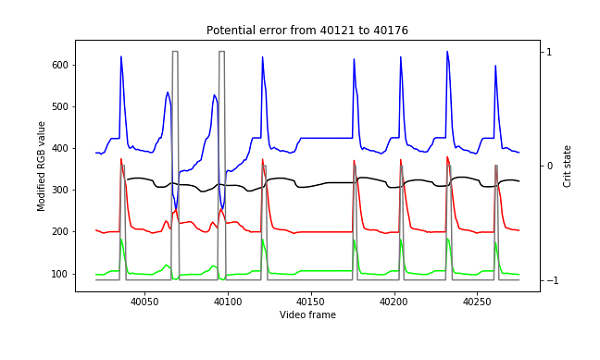
In the image above, you see a point where someone had to move slightly (between frames 40121 and 40176) so they would not be kicked from the game. To help with debugging, we added another element to the plot, showing the current state of our crit detection algorithm; we used -1 to denote “no attack,” 0 to denote a non-crit, and 1 to denote a crit.
Limitations and Future Work
While there is a lot that can be learned from our data, we’d like to acknowledge several limitations of our work.
- The data that we gathered was in the practice tool only, which means it may not be relevant to other game modes. We think it would be odd for Riot to implement a different algorithm in different game modes, but if they did, our results would be limited to the practice tool environment.
- It’s possible that Riot’s algorithm incorporates time between attacks or target switching, when a player changes the champion they are attacking. We did not account for this, and did not collect any data that involved switching targets.
- Certain champions and items like Tryndamere and Stormrazor have effects that modify nominal crit chance, which means that any potential crit smoothing algorithm would have to account for varying crit chances. We did not consider these cases.
- Because gathering data was so time consuming, we decided to record data only at 10% intervals of nominal crit chance. We did not record data for the following obtainable crit chances: 15%, 25%, 45%, 55%, 75%, 85%. If Riot’s crit algorithm is meaningfully different for these values, then our analysis missed that.
We think that a look at target switching would be an exciting next step, since it has significant implications for League players. If we did this, we’d also want to take into consideration time between attacks.
Alternatively: using a bit more math, there are many interesting methods we could use to try to understand our sequences of crits and how they relate to the probability of a critical strike. Essentially, all of this work involves modeling the probability of a crit given the history of crits so far, or—in the notation of probability theory, Pr(next attack is a crit | history of events), where “Pr” is short for “probability” and “|” means “given.” The current analysis only sought to understand values like Pr(next attack is a crit | the last attack was a crit) and Pr(next attack is a crit | the last attack was not a crit). However, there are other things we could study, such as Pr(next attack is a crit | k out of the last n attacks were crits), or Pr(next attack is a crit | proportion p of attacks so far have been crits).
Available Data
Finally, if you feel we missed something or you want to try your own hand at this analysis, we’ve made the data available. The videos will be uploaded to Youtube and any other information used in the analysis is available here. We’d love to see what you can come up with. Tweet at us with your result!

Join in on the fun!
At Doran's Lab, we strive to keep our process transparent and accessible. We've included the data corresponding to this article in a public Github repository for you to download and use.