In 2016, Riot Games made a post on their Dev Blog which grouped champions into classes and subclasses. By thinking carefully about the strengths and weaknesses of each champion as well as the state of the metagame, Riot was able to form useful categories of champions according to their playstyles and roles within a team. While Riot may have analyzed their own internal game data to help create these groups, we’re guessing that their final decisions were based mostly on the intuition of their developers and playtesters. This raises the question: in what sense do Riot’s groupings capture meaningful differences between champions, rather than the subjective opinions of the people that made them?
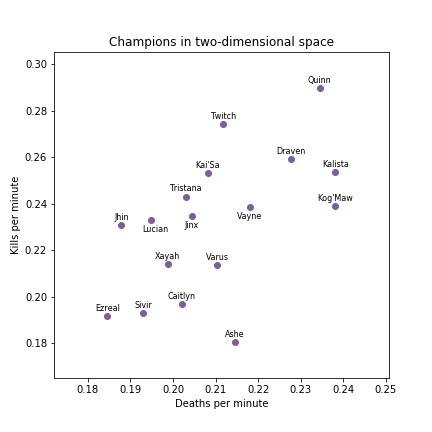
To get insight into this, we tried approaching the problem from a primarily data-driven perspective. We grouped champions using a statistical algorithm that groups together champions which are most similar to each other, where similarity is computed using measurable champion attributes. By using this algorithm, we limited the use of human intuition so that it had less of an impact on our final results. The hope is that by doing this, our results are more “objective,” in the sense that they depend more on the the data than on our opinions. This is useful because it can help identify similarities between champions that do not appear to be similar at first glance, and it also allows us to quickly rerun our clustering (grouping) at any time to recalibrate the grouping to reflect changes in champion ability or playing styles. It’s important to note, however, that this doesn’t mean our method is better: maybe our method is great for answering some questions, whereas Riot’s is better for others. In any case, we have some cool results and we hope that you will be able to glean some insights from them! If you’re an employee at Riot who works on creating classes of champions, maybe it will give you a new idea or help settle a disagreement with that colleague who is convinced that Mundo is a fighter, not a tank.
Asking the Right Question
Now that we know the type of question we want to answer (which champions are like each other?), we need to express this question in a way that math and statistics can help us answer. Here is how we formulated the question: if we have (i) a list of champions, (ii) a pre-specified number of groups (for example, “three groups”), and (iii) data relating to each of the champions, how can we assign each champion to exactly one group such that champions with similar data tend to be placed in the same group? In the field of machine learning and statistics, this type of problem is known as a clustering problem. Here, “clustering” refers to the process of assigning champions to different groups, aka clusters, using of each champion’s data.